In this paper, we introduce a novel path to general human motion generation by focusing on 2D space. Traditional methods have primarily generated human motions in 3D, which, while detailed and realistic, are often limited by the scope of available 3D motion data in terms of both the size and the diversity. To address these limitations, we exploit extensive availability of 2D motion data. We present Holistic-Motion2D, the first comprehensive and large-scale benchmark for 2D whole-body motion generation, which includes over 1M in-the-wild motion sequences, each paired with high-quality whole-body/partial pose annotations and textual descriptions. Notably, Holistic-Motion2D is ten times larger than the previously largest 3D motion dataset. We also introduce a baseline method, featuring innovative whole-body part-aware attention and confidence-aware modeling techniques, tailored for 2D Text-drivEN whole-boDy motion genERation, namely Tender. Extensive experiments demonstrate the effectiveness of Holistic-Motion2D and Tender in generating expressive, diverse, and realistic human motions. We also highlight the utility of 2D motion for various downstream applications and its potential for lifting to 3D motion.
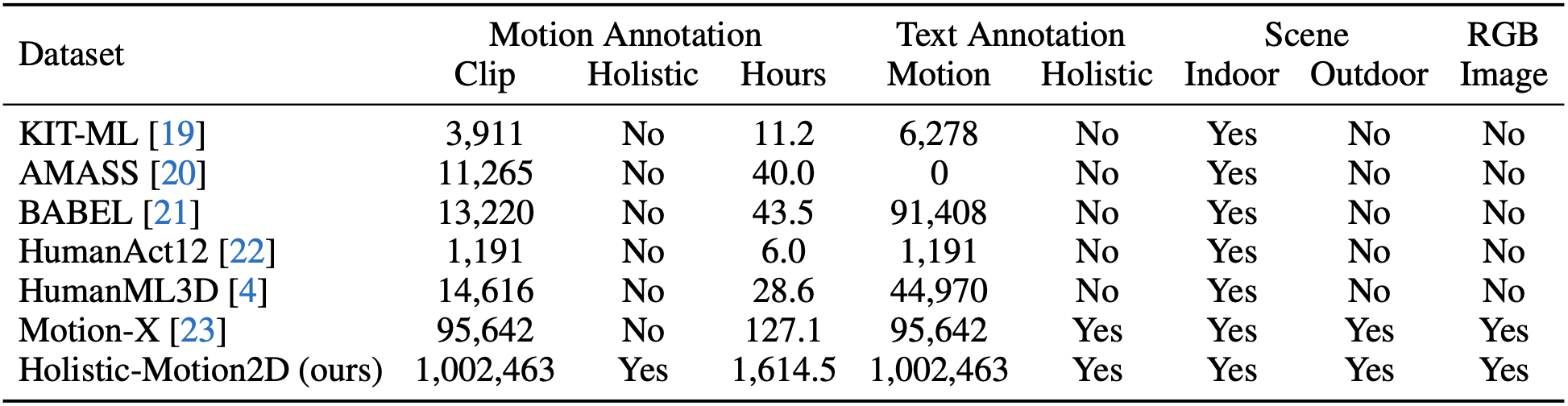
Comparison between our proposed Holistic-Motion2D and existing text-motion datasets. The video quantity of our Holistic-Motion2D is 10x larger than the previously largest 3D motion dataset, i.e., Motion-X.
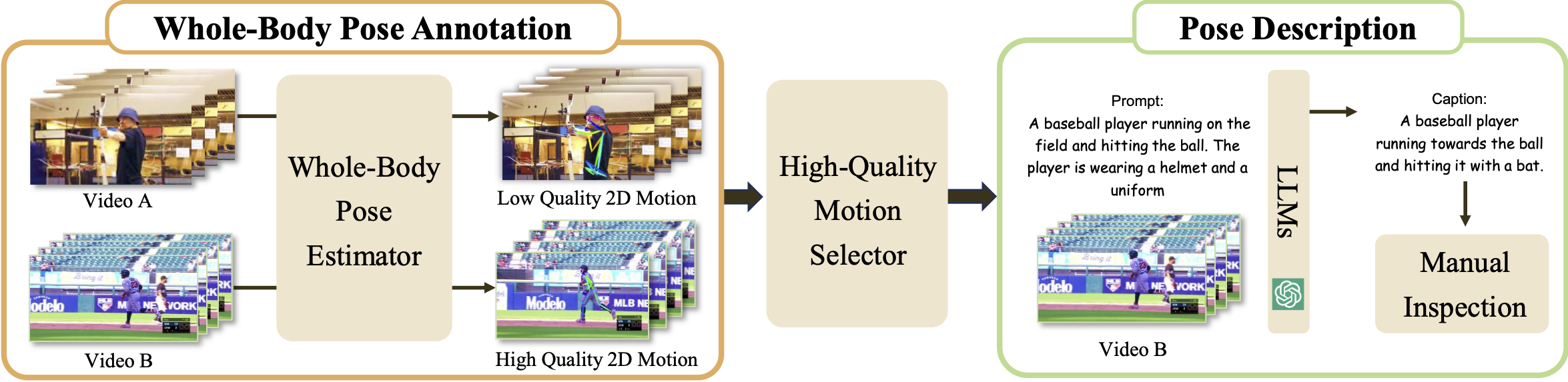
Overview of the keypoints and pose descriptions annotation pipeline of 2D whole-body motions.
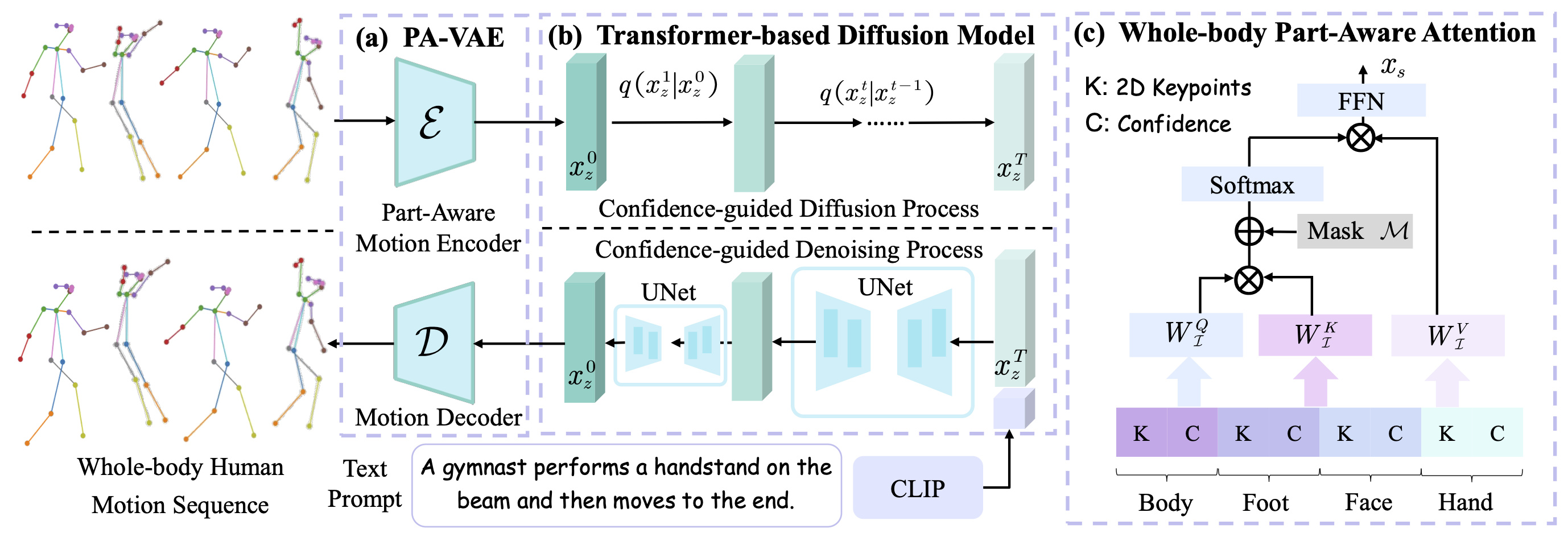
Overview of our Tender framework. (a) PA-VAE to embed whole-body part-aware spatio-temporal features into a latent space. (b) The diffusion model to generate realistic whole-body motions conditioned on texts. (c) Whole-body Part-Aware Attention to model spatial relations of different parts with CAG mechanism.
Qualitative results of our Tender compared with previous SOTA methods. Our Tender generates clearly more vivid human motions
and preserves the fidelity, together with superior temporal consistency.
Reference Image
DensePose (mapped from 2D keypoints)
Generated Video
The man in the middle is doing a dance move.
A man is performing a series of exercises with dumbbells.
A woman is lifting a barbell and then dropping it with both hands.
A woman is doing squats with dumbbells in a gym.
Visualization results of pose-guided human video generation using our proposed Tender model in multiple visual scenarios,
with a corresponding text prompt given below and a reference image given on the left.
2D Human Motion
Lifted 3D Human Motion
A man is lifting weights while standing on a weight bench in the gym.
A man is lifting a barbell and performing a series of exercises.
A man is juggling three balls.
A woman is doing squats with dumbbells in a gym.
A man is doing a workout with dumbbells.
A man is performing exercises in a gym by lying on his back and rolling over to his stomach.
Visualization results of 3D motion lifting using our proposed Tender model in multiple visual scenarios,
with a corresponding text prompt given below.
The man is playing the piano with his hands.
A man is lifting weights in a gym. He is lifting the weights with both hands in a slow and steady motion.
The elderly man swinging a golf club in different directions and positions. The man is practicing his swing.
The man is performing a martial art routine. He is doing a series of punches and kicks and postures.
Visualization results of he generated 2D whole-body motions using our proposed Tender model in multiple visual scenarios,
with a corresponding text prompt given below.
[1] Jianrong Zhang, Yangsong Zhang, Xiaodong Cun, Shaoli Huang, Yong Zhang, Hongwei Zhao, Hongtao Lu, and Xi Shen. T2m-gpt: Generating human motion from textual descriptions with discrete representations. CVPR, 2023.
[2] Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, and Amit H Bermano. Human motion diffusion model. ICLR, 2023.
[3] Xin Chen, Biao Jiang, Wen Liu, Zilong Huang, Bin Fu, Tao Chen, and Gang Yu. Executing your commands via motion diffusion in latent space. CVPR, 2023.
@article{wang2024holistic,
title={Holistic-Motion2D: Scalable Whole-body Human Motion Generation in 2D Space},
author={Wang, Yuan and Wang, Zhao and Gong, Junhao and Huang, Di and He, Tong and Ouyang, Wanli and Jiao, Jile and Feng, Xuetao and Dou, Qi and Tang, Shixiang and Xu, Dan},
journal={arXiv preprint arXiv:},
year={2024}
}
 Holistic-Motion2D: Scalable Whole-body Human Motion Generation in 2D Space
Holistic-Motion2D: Scalable Whole-body Human Motion Generation in 2D Space